I'm going to start off this post with a film clip. It's 4 minutes long, but I hope you'll watch it. The scene is from my favorite film ever, Sneakers, and in this clip, Robert Redford and his crack team of penetration testers root through a guy's trash.
Whose trash are they rooting through? A character named Werner Brandes.
Why are they rooting through his trash? They want to learn about Werner, his personality, his routine, his weaknesses. Because Robert Redford wants to find a way to get close to Werner and exploit him to break into his workplace.
Let's watch.
Whose trash are they rooting through? A character named Werner Brandes.
Why are they rooting through his trash? They want to learn about Werner, his personality, his routine, his weaknesses. Because Robert Redford wants to find a way to get close to Werner and exploit him to break into his workplace.
Let's watch.
Toward a creepier definition of big data
Let's keep that clip in our back pocket for a few minutes, so that I can ask a question.
What exactly is it about big data that makes it so creepy?
Here's the typical definition you'll see for "big data:"
Big data is the collection of data sets too large and complex to be stored and processed using conventional approaches.
There's nothing creepy about large amounts of storage, though, is there? So then what is it? Well, let's take a look at some "big data" illustrations from vendors' literature to get a better definition.
We'll have to start with the most popular of big data images: the glowing binary tunnel of big data.
What exactly is it about big data that makes it so creepy?
Here's the typical definition you'll see for "big data:"
Big data is the collection of data sets too large and complex to be stored and processed using conventional approaches.
There's nothing creepy about large amounts of storage, though, is there? So then what is it? Well, let's take a look at some "big data" illustrations from vendors' literature to get a better definition.
We'll have to start with the most popular of big data images: the glowing binary tunnel of big data.

The blue binary data tunnel.
Obviously, there's a notion of data collection here (in binary of course...and blue, always blue), but the light around the corner seems to betray something more than collection. It's like the briefcase in Pulp Fiction. We don't know what's in the briefcase, but we know it's important. It's glowing. It's special.
And below we have three images from big data technology vendor sites. Eyes, eyes, and more eyes. Once again, we've got binary (the last image has some 2s in it as well for some unknown reason). There's an element, then, of seeing something in this blue binary data. Discovery.
And below we have three images from big data technology vendor sites. Eyes, eyes, and more eyes. Once again, we've got binary (the last image has some 2s in it as well for some unknown reason). There's an element, then, of seeing something in this blue binary data. Discovery.
 |  |  |
Next, we've got images of keys and locks. In one image a binary key unlocks a hex lock (?), and in another image, a key unlocks a lock in an eyeball made from both circuit boards and binary. Get an editor, people!
 |  |
 |  |
So what do these images tell us? That big data allows us to access something or do something that previously had been unavailable to us.
Here then is a new definition of big data based on this imagery:
Big data is the collection of data sets too large to be stored using conventional approaches for the purpose of enabling organizations to discover and act on insights in the data.
Is that creepy? I'm not so sure we're there yet.
After all, since the early nineties the airline industry has been collecting large data sets, discovering patterns in demand and elasticity in the data, and using those discoveries to lock and unlock fare classes programmatically in order to maximize revenue on flights. This practice is called revenue management or yield management, and it predates the creepiness of big data by decades.
And what about FICO's Falcon program for realtime fraud detection in streams of credit card data? That thing has been around since the mid nineties. But I think all of us appreciate that programs like Falcon lock our stolen cards down pretty quick.
So what is it then? Well, let's take a peek at some of the recent examples of big data creepiness.
Here then is a new definition of big data based on this imagery:
Big data is the collection of data sets too large to be stored using conventional approaches for the purpose of enabling organizations to discover and act on insights in the data.
Is that creepy? I'm not so sure we're there yet.
After all, since the early nineties the airline industry has been collecting large data sets, discovering patterns in demand and elasticity in the data, and using those discoveries to lock and unlock fare classes programmatically in order to maximize revenue on flights. This practice is called revenue management or yield management, and it predates the creepiness of big data by decades.
And what about FICO's Falcon program for realtime fraud detection in streams of credit card data? That thing has been around since the mid nineties. But I think all of us appreciate that programs like Falcon lock our stolen cards down pretty quick.
So what is it then? Well, let's take a peek at some of the recent examples of big data creepiness.

There's the case of the Android app "Brightest Flashlight Free," which tracked users' GPS locations for the purpose of passing that data on later at a profit.
We've all heard the Eric Schmidt quote, "We know where you are. We know where you've been. We can more or less know what you're thinking about.”
Little did we know the "we" in his sentence was any company able to code up an app that turned on a cameraphone's flash.
And how about the case of Shutterfly predicting (albeit poorly) which users likely just had a kid, so that they could market them on preserving these precious moments? We don't really know what data Shutterfly used here. We don't even know if it was internal data or if they bought it from a broker. But it smelled funny to a lot of customers.
We've all heard the Eric Schmidt quote, "We know where you are. We know where you've been. We can more or less know what you're thinking about.”
Little did we know the "we" in his sentence was any company able to code up an app that turned on a cameraphone's flash.
And how about the case of Shutterfly predicting (albeit poorly) which users likely just had a kid, so that they could market them on preserving these precious moments? We don't really know what data Shutterfly used here. We don't even know if it was internal data or if they bought it from a broker. But it smelled funny to a lot of customers.

Nope, no predicted bundle of joy here.
For a little public sector flavor, we have the Chicago PD predicting and targeting possible future criminals for a bit of harassment, which they have called (in what is perhaps the best bit of pre-crime euphemistic language ever) a "custom notification."

A custom notification from the fuzz.
The Chicago PD had access to things like address/neighborhood, high school graduation, gender, and age, and all they did was bring this data together in an arguably discriminatory modeling soup and target the likely offenders without a whole lot of justification that harassment prior to a crime would reduce the incidence of criminal behavior.
So what's the difference between Delta performing revenue management or FICO running antifraud models and what we see today?
In the present world of big data, there are more companies, combining more data sources, to produce more targeted actions.
So what's the difference between Delta performing revenue management or FICO running antifraud models and what we see today?
In the present world of big data, there are more companies, combining more data sources, to produce more targeted actions.
More Companies
Let's recall the Sneakers clip we just watched. Robert Redford's team was no Fortune 500 company. They're just a small band of misfits, completely unknown as an organization to their target, to any regulating body, or to anyone, really. Yet they had the ability to pull data from the DMV, credit reports, organizational memberships, the household trash, etc. and use it to predict things about Werner Brandes (he's anal retentive, for one). That's the world we now live in, except teams of sneakers are everywhere, your household trash data can be pulled via API, and we're all poor Werner.
The Chicago PD and Brightest Flashlight Free are a far cry in size, budget, and sophistication from Delta or FICO. More companies can collect and use large amounts of data. And that's worrisome in the same way that giving everyone a gun is worrisome.
Sure, if everyone has a gun, then we're all armed, and that's supposedly safe in a mutually assured destruction kind of way. But on the flip side...now everyone has a gun including people who garner less public scrutiny and who don't know how to use their guns.
Does the Chicago PD understand that by delivering "custom notifications" to potential criminals that their potentially discriminatory actions are affecting, perhaps negatively, those same neighborhoods that will generate future streams of data for use in their models? Probably not.
So what we have then in the big data world, through more accessible software (open source data analysis and ML tools), accessible data (APIs, datasets for purchase, etc.), and cheaper compute power, is a situation in which we're arming organizations large and small, to use data to make potentially harmful decisions (e.g. precrime decisions, credit approval, job hiring decisions, admissions decisions, etc.).
And what creeps you out more? 10 elephants with rocket launchers on their backs or millions of mice with lasers?
The Chicago PD and Brightest Flashlight Free are a far cry in size, budget, and sophistication from Delta or FICO. More companies can collect and use large amounts of data. And that's worrisome in the same way that giving everyone a gun is worrisome.
Sure, if everyone has a gun, then we're all armed, and that's supposedly safe in a mutually assured destruction kind of way. But on the flip side...now everyone has a gun including people who garner less public scrutiny and who don't know how to use their guns.
Does the Chicago PD understand that by delivering "custom notifications" to potential criminals that their potentially discriminatory actions are affecting, perhaps negatively, those same neighborhoods that will generate future streams of data for use in their models? Probably not.
So what we have then in the big data world, through more accessible software (open source data analysis and ML tools), accessible data (APIs, datasets for purchase, etc.), and cheaper compute power, is a situation in which we're arming organizations large and small, to use data to make potentially harmful decisions (e.g. precrime decisions, credit approval, job hiring decisions, admissions decisions, etc.).
And what creeps you out more? 10 elephants with rocket launchers on their backs or millions of mice with lasers?
More Data...Sources
When we look at airline revenue management or FICO's Falcon program, we see massive amounts of data lying under complex models, but these efforts used one source of data. In the airline industry they used demand data to predict demand. In the credit card industry, transaction data was used to predict transaction fraud.
But this isn't the case today. Just as we saw in the Sneakers clip, where the team combined public data with location data and transactional data (Werner's garbage), companies today combine data sources to give themselves more predictive power than any one source alone could offer. When it comes to combining data streams, 1+1=3. That's why Facebook recently acquired credit card purchase data from Axciom to combine with its ad impression data -- those two sources in isolation are somewhat interesting, but when combined, they create a far more powerful picture of what it takes to market successfully to someone.
In the case of the Chicago PD, we see the combination of multiple data sources (crime data, demographic data, education data, etc.) to support a modeling effort. This combination of data, including data that a company itself may not have even generated, supports the ability for just about any organization to get into the big data game.
Obviously, the internet has created more and more streams of our data to be accessed by the originating companies as well as other companies to whom they might pass it. That's why the Brightest Flashlight Free was free in the first place. So that a stream of GPS data might be resold. And the proliferation of mobile devices, connected appliances (the Tesla I wish I owned, my Samsung washer machine, Nest), and wearables ensure that these data sources will only increase in number and in the scope of our lives that they can document.
In other words, it's not the number of records that adds a creep factor to big data. Lots of large data sets aren't creepy. The "big" in big data also has to do with the number of data sources a company can access, the variety in those streams' origins, and the scope of our lives that those streams cover.
But this isn't the case today. Just as we saw in the Sneakers clip, where the team combined public data with location data and transactional data (Werner's garbage), companies today combine data sources to give themselves more predictive power than any one source alone could offer. When it comes to combining data streams, 1+1=3. That's why Facebook recently acquired credit card purchase data from Axciom to combine with its ad impression data -- those two sources in isolation are somewhat interesting, but when combined, they create a far more powerful picture of what it takes to market successfully to someone.
In the case of the Chicago PD, we see the combination of multiple data sources (crime data, demographic data, education data, etc.) to support a modeling effort. This combination of data, including data that a company itself may not have even generated, supports the ability for just about any organization to get into the big data game.
Obviously, the internet has created more and more streams of our data to be accessed by the originating companies as well as other companies to whom they might pass it. That's why the Brightest Flashlight Free was free in the first place. So that a stream of GPS data might be resold. And the proliferation of mobile devices, connected appliances (the Tesla I wish I owned, my Samsung washer machine, Nest), and wearables ensure that these data sources will only increase in number and in the scope of our lives that they can document.
In other words, it's not the number of records that adds a creep factor to big data. Lots of large data sets aren't creepy. The "big" in big data also has to do with the number of data sources a company can access, the variety in those streams' origins, and the scope of our lives that those streams cover.
More Targeted

In the case of revenue management in the mid-nineties, sure, closing a fare class and raising the price of an airline ticket was, personally, a pain in the ass. But that revenue management wasn't personal per se. The fare class that gets closed likely gets closed for everyone.
Contrast that with Shutterfly predicting who's pregnant and who's not. That's personal. The Chicago PD knocking on your door before you've done anything wrong is personal. The data that was tracked by your flashlight app wasn't sold in aggregate. No, individual location data was sold.
There's an upside to personal. Like when Disney talks about tracking everyone inside their parks to provide a "personalized experience." Creepy, yes. But when the park's attractions are customized to your interests, that's kinda nice.
But there's a risky side to personal, isn't there? Just as Robert Redford's team of sneakers use Werner's personal information to target him with the perfect computer date, so now can companies target us. What's a "personalized notification" from the cops? That might just be profiling or discrimination. And what's another word for highly personalized advertising that leverages data on your insecurities? We might just as well call that manipulation. And when organizations discriminate against us and manipulate us, that all sums up to a loss of control (agency, humanity).
It used to be that the ad industry had only advertising atom bombs at their disposal. Tactics like "sex sells." Now they've got data-powered advertising drone strikes. Things like, "Diet pills sell...not to everyone, but certainly to people with status posts and photos like you."
So let's take another swing at defining big data:
Big data is the collection and combination of diverse data sets too large to be stored using conventional approaches to enable organizations large and small to discover and act on insights in the data for the purpose of controlling individuals and targeted groups of people.
Ooooo, that gave me chills.
Contrast that with Shutterfly predicting who's pregnant and who's not. That's personal. The Chicago PD knocking on your door before you've done anything wrong is personal. The data that was tracked by your flashlight app wasn't sold in aggregate. No, individual location data was sold.
There's an upside to personal. Like when Disney talks about tracking everyone inside their parks to provide a "personalized experience." Creepy, yes. But when the park's attractions are customized to your interests, that's kinda nice.
But there's a risky side to personal, isn't there? Just as Robert Redford's team of sneakers use Werner's personal information to target him with the perfect computer date, so now can companies target us. What's a "personalized notification" from the cops? That might just be profiling or discrimination. And what's another word for highly personalized advertising that leverages data on your insecurities? We might just as well call that manipulation. And when organizations discriminate against us and manipulate us, that all sums up to a loss of control (agency, humanity).
It used to be that the ad industry had only advertising atom bombs at their disposal. Tactics like "sex sells." Now they've got data-powered advertising drone strikes. Things like, "Diet pills sell...not to everyone, but certainly to people with status posts and photos like you."
So let's take another swing at defining big data:
Big data is the collection and combination of diverse data sets too large to be stored using conventional approaches to enable organizations large and small to discover and act on insights in the data for the purpose of controlling individuals and targeted groups of people.
Ooooo, that gave me chills.
We Can't Keep Track of our Data
 Agatha Christie couldn't help but leak health data
Agatha Christie couldn't help but leak health data Just like Werner Brandes couldn't keep track of what went into his household trash, we can't keep track of the data we generate anymore. Ever run Little Snitch on your computer to see where your data is going? The number of ad networks, dynamic content providers, and online analytics platforms that tag along on a single connection to cnn.com will blow your mind out your eyeballs.
And even if we could keep track of who's rooting through our trash, how can we possibly keep track of its potential uses?
When Agatha Christie pushed data out into the world in the form of her novels, did she have any idea those sentences would be used to diagnose her with Alzheimer's?
Just like the "folded tube of Crest" in the Sneakers clip betrayed Werner Brandes' personality, we have no idea what the data-cum-bathroom-trash of our lives is betraying about us. Which then begs the question: while in the U.S. (and in most of the developed world) Protected Health Information is a category of data strictly guarded by law, do these protections matter anymore?
If a model can look at my posts on social media and predict my health status with some level of certainty, does PHI cease to exist as a category? Is all information Protected Health Information?
People are not made up of silos. There is not a health category to John Foreman and a data scientist category to John Foreman and a good-times-on-a-saturday-night category to John Foreman. We are always our whole selves, and the data we generate will betray us holistically and in unexpected ways. Just because I'm at work doesn't mean that I haven't brought coffee breath from home in with me.
And even if we could keep track of who's rooting through our trash, how can we possibly keep track of its potential uses?
When Agatha Christie pushed data out into the world in the form of her novels, did she have any idea those sentences would be used to diagnose her with Alzheimer's?
Just like the "folded tube of Crest" in the Sneakers clip betrayed Werner Brandes' personality, we have no idea what the data-cum-bathroom-trash of our lives is betraying about us. Which then begs the question: while in the U.S. (and in most of the developed world) Protected Health Information is a category of data strictly guarded by law, do these protections matter anymore?
If a model can look at my posts on social media and predict my health status with some level of certainty, does PHI cease to exist as a category? Is all information Protected Health Information?
People are not made up of silos. There is not a health category to John Foreman and a data scientist category to John Foreman and a good-times-on-a-saturday-night category to John Foreman. We are always our whole selves, and the data we generate will betray us holistically and in unexpected ways. Just because I'm at work doesn't mean that I haven't brought coffee breath from home in with me.
Maybe Companies Will Run Out of Things To Say
We've just about reached "peak creepiness" in this blog post. So let's try to find our way back down to a more level-headed view of all this.
Here's one counterpoint to this unnerving development I've raised in the past: sure these companies know everything about us, but do they really have all the content they need to target us?
I had a friend recently who said something like, "I dare all these websites to try to get me to engage with their ads. I don't buy anything, listen to anything, or wear anything, unless I'm getting the recommendation from a friend. No ad could possibly fathom my tastes."
I don't doubt this friend. But perhaps companies don't need to find the perfect ad for him. Maybe they just need to change his personality temporarily until one of their current ads is a match.
As I pointed out in my previous post, Facebook's recent emotional manipulation experiment demonstrates that while companies can target us with content using big data, they can also target content with us. In other words, they can draw users emotionally nearer to their ads' targeted emotional states (insecure, feeling fat, whatever) by using tangential content (our friends posts on Facebook) to make us feel a certain way.
So if these companies aren't going to run out of data-guided ad strikes, what can we do?
Here's one counterpoint to this unnerving development I've raised in the past: sure these companies know everything about us, but do they really have all the content they need to target us?
I had a friend recently who said something like, "I dare all these websites to try to get me to engage with their ads. I don't buy anything, listen to anything, or wear anything, unless I'm getting the recommendation from a friend. No ad could possibly fathom my tastes."
I don't doubt this friend. But perhaps companies don't need to find the perfect ad for him. Maybe they just need to change his personality temporarily until one of their current ads is a match.
As I pointed out in my previous post, Facebook's recent emotional manipulation experiment demonstrates that while companies can target us with content using big data, they can also target content with us. In other words, they can draw users emotionally nearer to their ads' targeted emotional states (insecure, feeling fat, whatever) by using tangential content (our friends posts on Facebook) to make us feel a certain way.
So if these companies aren't going to run out of data-guided ad strikes, what can we do?
Maybe We Can Own Our Own Data
Let's talk about being invited to a backyard party at Ryan Gosling's house.
If Ryan (we're on a first name basis) invites me over to his party, do I have to go?
Nope.
But what if all my friends are going? I don't want to be the odd man out!
Do I have to go to Ryan Gosling's party?
The answer is still no.
So, then, I decide to go of my own accord. And I play croquet.
A lovely time is had by all.
When the party is done, can I go to Ryan Gosling and say, "Hey Ryan. Great party. Thanks for having me over to your backyard. But those memories you have of us playing croquet together...I need you to give me those memories. I own them."
Ryan Gosling would probably look at you like you're crazy.
So how is using Facebook any different? Do you own the data you give to Facebook any more than you own Ryan Gosling's memories?
This is an unfair comparison in one way: when you use Facebook you actually have to contract with them through accepting their terms of use. The law, especially in the US, allows folks great freedom to contract. So you've explicitly, legally permitted Facebook to remember you playing croquet at Ryan Gosling's house when you posted that status about it.
The trade-off here is not between Facebook owning your Facebook data and you owning it. Either you agree to be on Facebook, in which case they have data on you, or you don't agree, in which case you do not own your Facebook data. Why don't you own it? Because it doesn't exist.
So the opposite of other companies owning and managing our data is oftentimes no data existing at all, so the "we own our data," "we are the data," "we the data," "we = data" argument falls apart a little bit.
And who's going to pay for all this infrastructure on which we will potentially own and manage our own data even if we did have a claim over it? I doubt most consumers would be willing to pay. We're not even willing to pay for Facebook.
All of that said, I believe that we can stanch the flow of data to companies. Sure, data must be passed to LinkedIn when I use the mobile app, but it often seems they're overasking. Systems can be developed that limit what apps ask for to what they might reasonably need.
Ryan Gosling can remember my croquet game, but he doesn't need to follow me into the shower.
If Ryan (we're on a first name basis) invites me over to his party, do I have to go?
Nope.
But what if all my friends are going? I don't want to be the odd man out!
Do I have to go to Ryan Gosling's party?
The answer is still no.
So, then, I decide to go of my own accord. And I play croquet.
A lovely time is had by all.
When the party is done, can I go to Ryan Gosling and say, "Hey Ryan. Great party. Thanks for having me over to your backyard. But those memories you have of us playing croquet together...I need you to give me those memories. I own them."
Ryan Gosling would probably look at you like you're crazy.
So how is using Facebook any different? Do you own the data you give to Facebook any more than you own Ryan Gosling's memories?
This is an unfair comparison in one way: when you use Facebook you actually have to contract with them through accepting their terms of use. The law, especially in the US, allows folks great freedom to contract. So you've explicitly, legally permitted Facebook to remember you playing croquet at Ryan Gosling's house when you posted that status about it.
The trade-off here is not between Facebook owning your Facebook data and you owning it. Either you agree to be on Facebook, in which case they have data on you, or you don't agree, in which case you do not own your Facebook data. Why don't you own it? Because it doesn't exist.
So the opposite of other companies owning and managing our data is oftentimes no data existing at all, so the "we own our data," "we are the data," "we the data," "we = data" argument falls apart a little bit.
And who's going to pay for all this infrastructure on which we will potentially own and manage our own data even if we did have a claim over it? I doubt most consumers would be willing to pay. We're not even willing to pay for Facebook.
All of that said, I believe that we can stanch the flow of data to companies. Sure, data must be passed to LinkedIn when I use the mobile app, but it often seems they're overasking. Systems can be developed that limit what apps ask for to what they might reasonably need.
Ryan Gosling can remember my croquet game, but he doesn't need to follow me into the shower.
At Least I Can Own My Identity, Right?
 William Weld's Viagra prescription can't hide
William Weld's Viagra prescription can't hide This is the European approach. Sure, you can contract with Facebook and give them your data, but if it's got a personal identifier on it, like your name or email address, then you get some control over what's done with that identified data.
So companies are left with the option of anonymizing your data by stripping it of personal identifiers before passing it on.
That sounds good at first, and indeed, I think it's a regulatory step worth taking. But just like Agatha Christie Alzheimer's, our identity is embedded in everything we do. Our identity is not separable from the rest of us.
In the case of Werner Brandes in the Sneakers clip, it took two data points of timestamped location data (when he left work on two different days) to personally identify him. No name or email address needed to single him out personally. And Werner's problem is our problem -- it turns out that anonymizing your personal data is very, very hard. Maybe even impossible. William Weld, the once governor of Massachusetts, learned this when his personal medical records were de-anonymized using basic public information (the zipcode where he lived, his age, gender, ethnicity).
So, sure, you can own your personal identifiers. And that'd work if your personal identity wasn't stamped over everything else you did. Brightest Flashlight Free could watch my GPS signal travel from my address in Avondale Georgia to my office next to Georgia Tech once or twice, cross-reference that with some property records, and they'd have my location data labeled.
So companies are left with the option of anonymizing your data by stripping it of personal identifiers before passing it on.
That sounds good at first, and indeed, I think it's a regulatory step worth taking. But just like Agatha Christie Alzheimer's, our identity is embedded in everything we do. Our identity is not separable from the rest of us.
In the case of Werner Brandes in the Sneakers clip, it took two data points of timestamped location data (when he left work on two different days) to personally identify him. No name or email address needed to single him out personally. And Werner's problem is our problem -- it turns out that anonymizing your personal data is very, very hard. Maybe even impossible. William Weld, the once governor of Massachusetts, learned this when his personal medical records were de-anonymized using basic public information (the zipcode where he lived, his age, gender, ethnicity).
So, sure, you can own your personal identifiers. And that'd work if your personal identity wasn't stamped over everything else you did. Brightest Flashlight Free could watch my GPS signal travel from my address in Avondale Georgia to my office next to Georgia Tech once or twice, cross-reference that with some property records, and they'd have my location data labeled.
Privacy Pragmatism: Regulate Sausage, not Cats
Let's say that I want to prevent cats from being put into sausages.

Help me.
How do I go about that? Do I regulate cats at birth? If I know the cat isn't born in a sausage factory, then it's less likely to end up in sausage, maybe? Do I govern how cats can move from place to place or who can own a cat? That way I'll know if a cat moves near a sausage factory.
It seems easiest to just perform inspections of sausage factories themselves. It's not that cats exist, that cats roam, that cats can be herded or collected. If I care about how cats are used, then I should inspect possibly dangerous usage points.
This same argument, called "privacy pragmatism," can be made for data.
There's no way we can keep tabs on all data collection and retention. It's hard to know where all the data is going and indeed how it might be used to predict things we didn't intend for.
So what if we, instead, focus in on the things we don't want certain types of data to be used for and keep an eye on them?
For example, if loan approvals are a concern, then perhaps we inspect those institutions that make loans to make sure the inputs into their models are on the up-and-up. If one of the predictors is discriminatory, that's where it'll rear its head -- right before it enters the risk model (like a sausage casing). If an institution has collected some data, but they're not using it to make their decisions, then it's like a cat that hangs out in the employee break room.
It seems easiest to just perform inspections of sausage factories themselves. It's not that cats exist, that cats roam, that cats can be herded or collected. If I care about how cats are used, then I should inspect possibly dangerous usage points.
This same argument, called "privacy pragmatism," can be made for data.
There's no way we can keep tabs on all data collection and retention. It's hard to know where all the data is going and indeed how it might be used to predict things we didn't intend for.
So what if we, instead, focus in on the things we don't want certain types of data to be used for and keep an eye on them?
For example, if loan approvals are a concern, then perhaps we inspect those institutions that make loans to make sure the inputs into their models are on the up-and-up. If one of the predictors is discriminatory, that's where it'll rear its head -- right before it enters the risk model (like a sausage casing). If an institution has collected some data, but they're not using it to make their decisions, then it's like a cat that hangs out in the employee break room.
Is There Another Way?
Let's take a look at some companies currently using big data and data science to do things that aren't terribly creepy.
  |  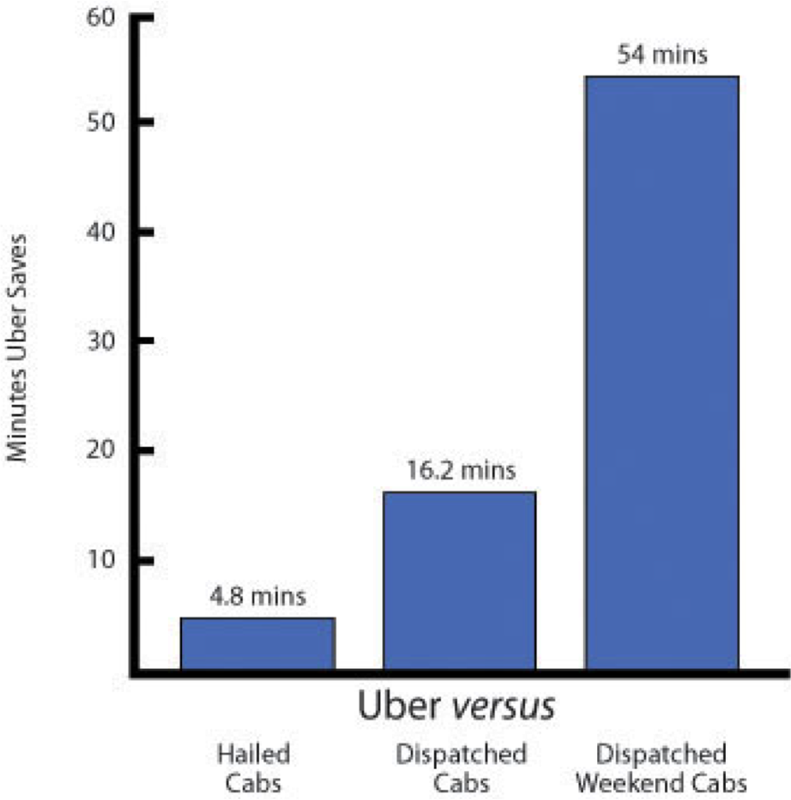 |
MailChimp uses its massive Email Genome Project database to allow certain users it deems "not a bot" to bypass CAPTCHA without filling it out. eHarmony uses data on things as basic as food preference to create matches (couples where both partners enjoy Hardees are doomed to failure). Uber uses data to power things like congestion pricing in order to reduce wait times. And Spotify powers its music discovery service with data.
Do these uses feel creepy? Certainly not Facebook levels of creepiness.
What's going on?
When we look at the creepiest of big data companies, what we see is that their customers (those who give them money) are not their data-generators. In the case of Facebook, its customers are advertisers and its users (us) give them data. In the case of Brightest Flashlight Free, the app developer acted as a data broker, selling location data on, so the users of its free app provided the data, while other companies who purchased that data were the actual customers.
Contrast that with MailChimp, Spotify, and eHarmony. All of these companies use subscriptions to receive money directly from their users. And Uber receives money directly from its riders.
The incentives are completely different, and those incentives are directly tied to how creepy a company will act. If my goal is to make money off of customer subscriptions then I am disincentivized from creeping those same customers out.
These not-so-creepy companies are using data to improve their user experience. In my opinion, this is the future for analytics; a future that's no longer at odds with those providing the data.
But until we get to that future, if you cut into your sausage and you hear a meow, you might want to talk to a health inspector.
Do these uses feel creepy? Certainly not Facebook levels of creepiness.
What's going on?
When we look at the creepiest of big data companies, what we see is that their customers (those who give them money) are not their data-generators. In the case of Facebook, its customers are advertisers and its users (us) give them data. In the case of Brightest Flashlight Free, the app developer acted as a data broker, selling location data on, so the users of its free app provided the data, while other companies who purchased that data were the actual customers.
Contrast that with MailChimp, Spotify, and eHarmony. All of these companies use subscriptions to receive money directly from their users. And Uber receives money directly from its riders.
The incentives are completely different, and those incentives are directly tied to how creepy a company will act. If my goal is to make money off of customer subscriptions then I am disincentivized from creeping those same customers out.
These not-so-creepy companies are using data to improve their user experience. In my opinion, this is the future for analytics; a future that's no longer at odds with those providing the data.
But until we get to that future, if you cut into your sausage and you hear a meow, you might want to talk to a health inspector.

 RSS Feed
RSS Feed